

Want to skip the post and see the good stuff directly? Here is the Github repo
Lead Generation is a very Lucrative business and people earn a ton of money just by finding emails to their client.
Today we will automate Lead Generation/Email Crawling with a simple python script.
Let's see what our end product will look like so that I won't waste your time in case you don't find this interesting.
Our crawler will visit all sub-pages of the provided website and look for emails and then save them in a CSV file.
See the code
First, let's see the code and then I will explain each step.
import re
import requests
import requests.exceptions
from urllib.parse import urlsplit, urljoin
from lxml import html
import sys
import csv
class EmailCrawler:
processed_urls = set()
unprocessed_urls = set()
emails = set()
def __init__(self, website: str):
self.website = website
self.unprocessed_urls.add(website)
self.headers = {
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/78.0.3904.70 Chrome/78.0.3904.70 Safari/537.36',
}
self.base_url = urlsplit(self.website).netloc
self.outputfile = self.base_url.replace('.','_')+'.csv'
# we will use this list to skip urls that contain one of these extension. This will save us a lot of bandwidth and speedup the crawling process
# for example: www.example.com/image.png --> this url is useless for us. we cannot possibly parse email from images and all other types of files.
self.garbage_extensions = ['.aif','.cda','.mid','.midi','.mp3','.mpa','.ogg','.wav','.wma','.wpl','.7z','.arj','.deb','.pkg','.rar','.rpm','.tar.gz','.z','.zip','.bin','.dmg','.iso','.toast','.vcd','.csv','.dat','.db','.dbf','.log','.mdb','.sav','.sql','.tar','.apk','.bat','.bin','.cgi','.pl','.exe','.gadget','.jar','.py','.wsf','.fnt','.fon','.otf','.ttf','.ai','.bmp','.gif','.ico','.jpeg','.jpg','.png','.ps','.psd','.svg','.tif','.tiff','.asp','.cer','.cfm','.cgi','.pl','.part','.py','.rss','.key','.odp','.pps','.ppt','.pptx','.c','.class','.cpp','.cs','.h','.java','.sh','.swift','.vb','.ods','.xlr','.xls','.xlsx','.bak','.cab','.cfg','.cpl','.cur','.dll','.dmp','.drv','.icns','.ico','.ini','.lnk','.msi','.sys','.tmp','.3g2','.3gp','.avi','.flv','.h264','.m4v','.mkv','.mov','.mp4','.mpg','.mpeg','.rm','.swf','.vob','.wmv','.doc','.docx','.odt','.pdf','.rtf','.tex','.txt','.wks','.wps','.wpd']
self.email_count = 0
def crawl(self):
"""
It will continue crawling untill the list unprocessed urls list is empty
"""
url = self.unprocessed_urls.pop()
print("CRAWL : {}".format(url))
self.parse_url(url)
if len(self.unprocessed_urls)!=0:
self.crawl()
else:
print('End of crawling for {} '.format(self.website))
print('Total urls visited {}'.format(len(self.processed_urls)))
print('Total Emails found {}'.format(self.email_count))
print('Dumping processed urls to {}'.format(self.base_url.replace('.','_')+'.txt'))
with open(self.base_url.replace('.','_')+'.txt' ,'w') as f:
f.write('\n'.join(self.processed_urls))
def parse_url(self, current_url: str):
"""
It will load and parse a given url. Loads it and finds all the url in this page.
It also filters the urls and adds them to unprocessed url list.
Finally it scrapes the emails if found on the page and the updates the email list
INPUT:
current_url: URL to parse
RETURN:
None
"""
#we will retry to visit a url for 5 times in case it fails. after that we will skip it in case if it still fails to load
response = requests.get(current_url, headers=self.headers)
tree = html.fromstring(response.content)
urls = tree.xpath('//a/@href') # getting all urls in the page
#Here we will make sure that we convert the sub domain to full urls
# example --> /about.html--> https://www.website.com/about.html
urls = [urljoin(self.website,url) for url in urls]
# now lets make sure that we only include the urls that fall under our domain i.e filtering urls that point outside our main website.
urls = [url for url in urls if self.base_url == urlsplit(url).netloc]
#removing duplicates
urls = list(set(urls))
#filtering urls that point to files such as images, videos and other as listed on garbage_extensions
#Here will loop through all the urls and skip them if they contain one of the extension
parsed_url = []
for url in urls:
skip = False
for extension in self.garbage_extensions:
if not url.endswith(extension) and not url.endswith(extension+'/'):
pass
else:
skip = True
break
if not skip:
parsed_url.append(url)
# finally filtering urls that are already in queue or already visited
for url in parsed_url:
if url not in self.processed_urls and url not in self.unprocessed_urls:
self.unprocessed_urls.add(url)
#parsing email
self.parse_emails(response.text)
# adding the current url to processed list
self.processed_urls.add(current_url)
def parse_emails(self, text: str):
"""
It scans the given texts to find email address and then writes them to csv
Input:
text: text to parse emails from
Returns:
bool: True or false (True if email was found on page)
"""
# parsing emails and then saving to csv
emails = set(re.findall(r'[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+', text, re.I))
#TODO: sometime "gFJS3amhZEg_z39D5EErVg@2x.png" gets accepted as email with the above regex. so for now i will check if email ends with jpeg,png and jpg
for email in emails:
skip_email = False
for checker in ['jpg','jpeg','png']:
if email.endswith(checker):
skip_email = True
break
if not skip_email:
if email not in self.emails:
with open(self.outputfile, 'a', newline='') as csvf:
csv_writer = csv.writer(csvf)
csv_writer.writerow([email])
self.email_count +=1
self.emails.add(email)
print(' {} Email found {}'.format(self.email_count,email))
if len(emails)!=0:
return True
else:
return False
print('WELCOME TO EMAIL CRAWLER')
try:
website = sys.argv[1]
except:
website = input("Please enter a website to crawl for emails:")
crawl = EmailCrawler(website)
crawl.crawl()
Let's understand what is happening here
First part init function
class EmailCrawler:
processed_urls = set()
unprocessed_urls = set()
emails = set()
def __init__(self, website: str):
self.website = website
self.unprocessed_urls.add(website)
self.headers = {
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/78.0.3904.70 Chrome/78.0.3904.70 Safari/537.36',
}
self.base_url = urlsplit(self.website).netloc
self.outputfile = self.base_url.replace('.','_')+'.csv'
# we will use this list to skip urls that contain one of these extension. This will save us a lot of bandwidth and speedup the crawling process
# for example: www.example.com/image.png --> this url is useless for us. we cannot possibly parse email from images and all other types of files.
self.garbage_extensions = ['.aif','.cda','.mid','.midi','.mp3','.mpa','.ogg','.wav','.wma','.wpl','.7z','.arj','.deb','.pkg','.rar','.rpm','.tar.gz','.z','.zip','.bin','.dmg','.iso','.toast','.vcd','.csv','.dat','.db','.dbf','.log','.mdb','.sav','.sql','.tar','.apk','.bat','.bin','.cgi','.pl','.exe','.gadget','.jar','.py','.wsf','.fnt','.fon','.otf','.ttf','.ai','.bmp','.gif','.ico','.jpeg','.jpg','.png','.ps','.psd','.svg','.tif','.tiff','.asp','.cer','.cfm','.cgi','.pl','.part','.py','.rss','.key','.odp','.pps','.ppt','.pptx','.c','.class','.cpp','.cs','.h','.java','.sh','.swift','.vb','.ods','.xlr','.xls','.xlsx','.bak','.cab','.cfg','.cpl','.cur','.dll','.dmp','.drv','.icns','.ico','.ini','.lnk','.msi','.sys','.tmp','.3g2','.3gp','.avi','.flv','.h264','.m4v','.mkv','.mov','.mp4','.mpg','.mpeg','.rm','.swf','.vob','.wmv','.doc','.docx','.odt','.pdf','.rtf','.tex','.txt','.wks','.wps','.wpd']
self.email_count = 0
We have defined the following Sets
- processed_urls --> will hold the URLs that we have visited(so that we won't visit the same URL twice)
- unprocessed_urls --> will hold the URLs that are on the queue to parse
- emails --> will hold the parsed emails.
We will use the base URL later to make sure our crawler doesn't visit outside URLs.
For example: if the user passes https://www.medium.com then the base URL would be medium.com. We will use this later to ensure that our crawler will only visit the URL within this domain.
crawl function
The crawl function is a starting point of our crawler. It will keep visiting all the URLs in the queue until we have visited every URL on the website.
def crawl(self):
"""
It will continue crawling untill the list unprocessed urls list is empty
"""
url = self.unprocessed_urls.pop()
print("CRAWL : {}".format(url))
self.parse_url(url)
if len(self.unprocessed_urls)!=0:
self.crawl()
else:
print('End of crawling for {} '.format(self.website))
print('Total urls visited {}'.format(len(self.processed_urls)))
print('Total Emails found {}'.format(self.email_count))
print('Dumping processed urls to {}'.format(self.base_url.replace('.','_')+'.txt'))
with open(self.base_url.replace('.','_')+'.txt' ,'w') as f:
f.write('\n'.join(self.processed_urls))
parse url function
Our parse_urls function is where extraction happens. Here we
- parse and filter all the URLs found on the given page.
- We filtered
duplicate URLs,URLs outside the domainandalready visited URLs - We will also make sure that we don't try to visit urls that lead to files such as jpg,mp4,zips.
- We finally parse the page for emails and then write them to a CSV file.
def parse_url(self, current_url: str):
"""
It will load and parse a given url. Loads it and finds all the url in this page.
It also filters the urls and adds them to unprocessed url list.
Finally it scrapes the emails if found on the page and the updates the email list
INPUT:
current_url: URL to parse
RETURN:
None
"""
# visiting the page
response = requests.get(current_url, headers=self.headers)
tree = html.fromstring(response.content)
urls = tree.xpath('//a/@href') # getting all urls in the page
#Here we will make sure that we convert the sub domain to full urls
# example --> /about.html--> https://www.website.com/about.html
urls = [urljoin(self.website,url) for url in urls]
# now lets make sure that we only include the urls that fall under our domain i.e filtering urls that point outside our main website.
urls = [url for url in urls if self.base_url == urlsplit(url).netloc]
#removing duplicates
urls = list(set(urls))
#filtering urls that point to files such as images, videos and other as listed on garbage_extensions
#Here will loop through all the urls and skip them if they contain one of the extension
parsed_url = []
for url in urls:
skip = False
for extension in self.garbage_extensions:
if not url.endswith(extension) and not url.endswith(extension+'/'):
pass
else:
skip = True
break
if not skip:
parsed_url.append(url)
# finally filtering urls that are already in queue or already visited
for url in parsed_url:
if url not in self.processed_urls and url not in self.unprocessed_urls:
self.unprocessed_urls.add(url)
#parsing email
self.parse_emails(response.text)
# adding the current url to processed list
self.processed_urls.add(current_url)
parse email function
It takes a text input and then finds emails on that text and finally writes these emails to a CSV file.
def parse_emails(self, text: str):
"""
It scans the given texts to find email address and then writes them to csv
Input:
text: text to parse emails from
Returns:
bool: True or false (True if email was found on page)
"""
# parsing emails and then saving to csv
emails = set(re.findall(r'[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+', text, re.I))
#TODO: sometime "gFJS3amhZEg_z39D5EErVg@2x.png" gets accepted as email with the above regex. so for now i will check if email ends with jpeg,png and jpg
for email in emails:
skip_email = False
for checker in ['jpg','jpeg','png']:
if email.endswith(checker):
skip_email = True
break
if not skip_email:
if email not in self.emails:
with open(self.outputfile, 'a', newline='') as csvf:
csv_writer = csv.writer(csvf)
csv_writer.writerow([email])
self.email_count +=1
self.emails.add(email)
print(' {} Email found {}'.format(self.email_count,email))
if len(emails)!=0:
return True
else:
return False
How do i run this code?
To get a local copy up and running follow these simple steps.
Installation
- Clone the Email-Crawler-Lead-Generator
git clone https://github.com/nOOBIE-nOOBIE/Email-Crawler-Lead-Generator.git
- Install dependencies
pip install -r requirements.txt
Usage
Simply pass the url as an argument
python email_crawler.py https://medium.com/
Output
➜ email_crawler python3 email_crawler.py https://medium.com/
WELCOME TO EMAIL CRAWLER
CRAWL : https://medium.com/
1 Email found press@medium.com
2 Email found u002F589e367c28ca47b195ce200d1507d18b@sentry.io
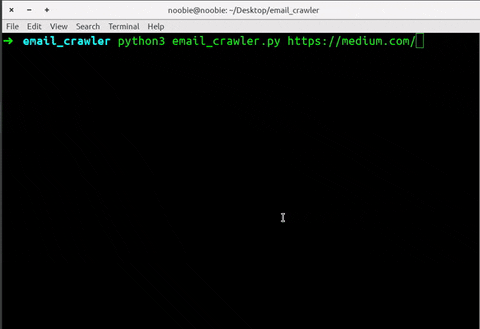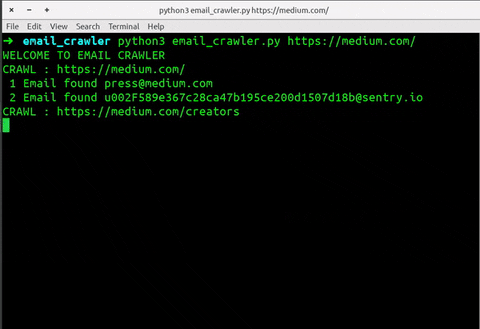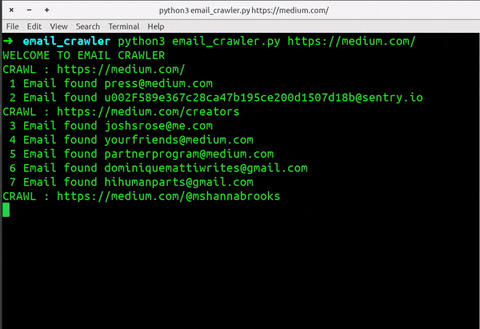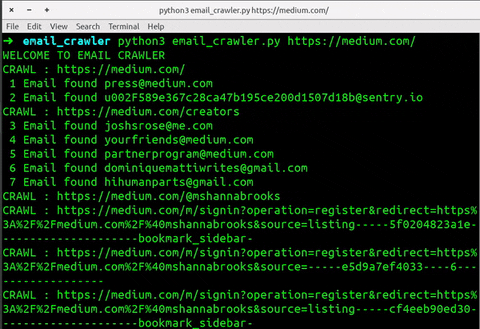
CRAWL : https://medium.com/creators
3 Email found joshsrose@me.com
4 Email found yourfriends@medium.com
5 Email found partnerprogram@medium.com
6 Email found dominiquemattiwrites@gmail.com
7 Email found hihumanparts@gmail.com
CRAWL : https://medium.com/@mshannabrooks
CRAWL : https://medium.com/m/signin?operation=register&redirect=https%3A%2F%2Fmedium.com%2F%40mshannabrooks&source=listing-----5f0204823a1e---------------------bookmark_sidebar-
CRAWL : https://medium.com/m/signin?operation=register&redirect=https%3A%2F%2Fmedium.com%2F%40mshannabrooks&source=-----e5d9a7ef4033----6------------------
If you have suggestions or find some issues.
Feel free to open issues or a Pull Request on github.
Thank you for reading